
科研動(dòng)態(tài)
基于雙向語(yǔ)義緩解語(yǔ)義漂移的知識(shí)圖譜多跳問(wèn)答
中文題目:基于雙向語(yǔ)義緩解語(yǔ)義漂移的知識(shí)圖譜多跳問(wèn)答
論文題目:Alleviating Semantic Drift in Multi-Hop Question Answering on Knowledge Graphs with Bidirectional Semantics
錄用期刊/會(huì)議:International Joint Conference on Neural Networks (IJCNN) (CCF C)
作者列表:
1)袁明才 中國(guó)石油大學(xué)(北京)人工智能學(xué)院 計(jì)算機(jī)科學(xué)與技術(shù) 碩21
2)魯 強(qiáng) 中國(guó)石油大學(xué)(北京)人工智能學(xué)院 智能科學(xué)與技術(shù)系 教師
3)曾顯豪 中國(guó)石油大學(xué)(北京)人工智能學(xué)院 計(jì)算機(jī)技術(shù) 碩23
4)Jake Luo University of Wisconsin Milwaukee Department of Health Informatics and Administration Associate Professor
5)李大偉 中國(guó)石油勘探開(kāi)發(fā)研究院 高級(jí)工程師
摘要:
知識(shí)圖譜多跳問(wèn)答利用知識(shí)圖譜(KG)的結(jié)構(gòu)信息來(lái)推斷答案。然而,KG在從問(wèn)題實(shí)體到答案實(shí)體的推理路徑上往往存在邊缺失。最近的研究集中在各種KG嵌入方法上,以獲得推理路徑的語(yǔ)義(稱為正向語(yǔ)義)來(lái)修復(fù)缺失的邊。但是,正向語(yǔ)義可能會(huì)隨著路徑變長(zhǎng)而漂移。本文提出了一種雙向語(yǔ)義嵌入與匹配方法(BSEM)來(lái)緩解正向語(yǔ)義漂移問(wèn)題。BSEM首先利用反向語(yǔ)義來(lái)推導(dǎo)推理路徑相反方向的語(yǔ)義。然后,BSEM構(gòu)建了一種兩階段學(xué)習(xí)方法來(lái)聯(lián)合學(xué)習(xí)雙向語(yǔ)義并找到正確答案。在兩階段學(xué)習(xí)方法中,聯(lián)合學(xué)習(xí)同時(shí)學(xué)習(xí)雙向語(yǔ)義,促進(jìn)兩者的交互;對(duì)比學(xué)習(xí)則用來(lái)提高反向語(yǔ)義推理區(qū)分正向語(yǔ)義推理答案中錯(cuò)誤答案的能力。在MetaQA和WebQSP兩個(gè)基準(zhǔn)測(cè)試上的實(shí)驗(yàn)表明,BSEM優(yōu)于PullNet、EmQL、LEGO、EmbedKGQA和KGT5五種基準(zhǔn)方法。特別是在不完整的KG—WebQSP實(shí)驗(yàn)設(shè)置中,與除EmQL外的其他四種方法相比,BSEM的準(zhǔn)確率分別提高了13.1%、12.0%、5.4%和10.0%。
設(shè)計(jì)與實(shí)現(xiàn):
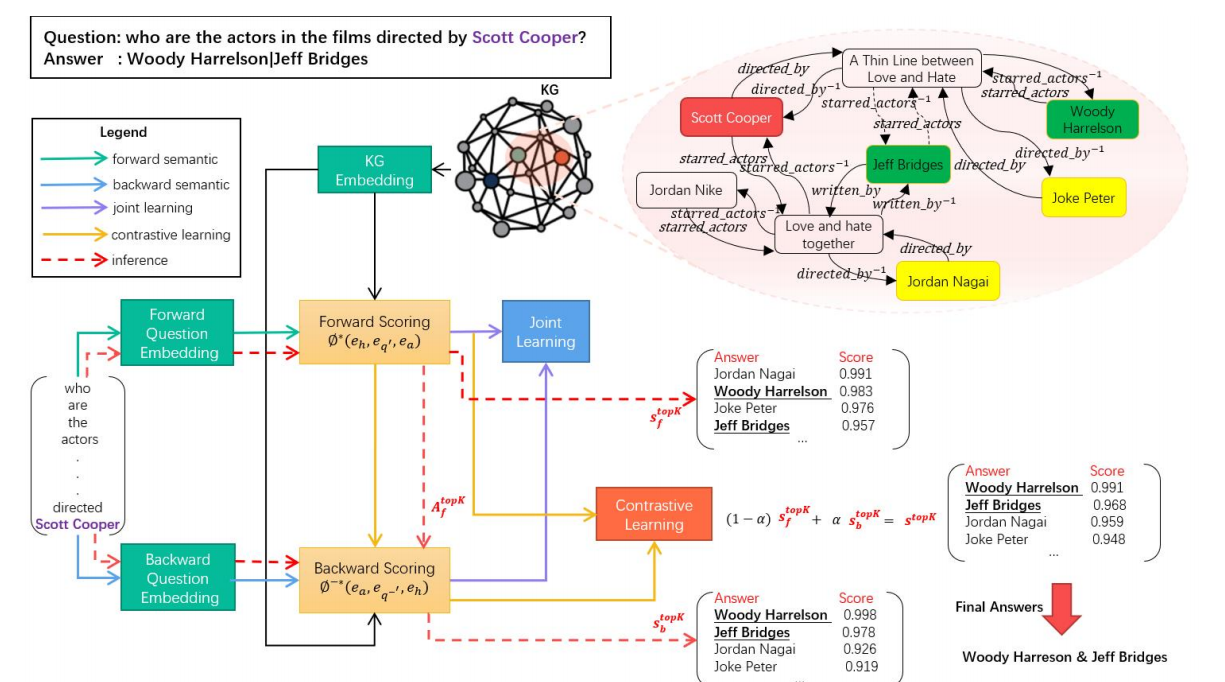
圖1 BSEM的模型結(jié)構(gòu)
雙向語(yǔ)義嵌入與匹配方法(BSEM)模型結(jié)構(gòu)如圖1所示,包括三個(gè)模塊:知識(shí)圖譜嵌入模塊、問(wèn)題嵌入模塊和語(yǔ)義推理模塊。知識(shí)圖譜嵌入模塊利用了一種稱為ComplEx的知識(shí)圖譜嵌入方法,用于學(xué)習(xí)知識(shí)圖譜中所有實(shí)體和關(guān)系的嵌入向量。問(wèn)題嵌入模塊用于生成給定問(wèn)題的正向和反向語(yǔ)義表示。語(yǔ)義推理模塊由正向推理![]() 和反向推理
和反向推理![]() 組成,利用前兩個(gè)模塊生成的語(yǔ)義向量進(jìn)行推理計(jì)算,并對(duì)候選答案進(jìn)行排序。在模型訓(xùn)練階段,設(shè)計(jì)了一種兩階段學(xué)習(xí)方法,采用聯(lián)合學(xué)習(xí)和對(duì)比學(xué)習(xí)來(lái)訓(xùn)練正向和反向推理。在模型預(yù)測(cè)階段,將正向和反向推理結(jié)合起來(lái),使用反向推理對(duì)正向推理的答案進(jìn)行反向檢驗(yàn),從而推斷出正確的答案。這種方法充分利用了知識(shí)圖譜中實(shí)體之間的正反向推理語(yǔ)義信息,不僅提高了問(wèn)答系統(tǒng)的性能和準(zhǔn)確性,同時(shí)答案也具備一定的可解釋性。
組成,利用前兩個(gè)模塊生成的語(yǔ)義向量進(jìn)行推理計(jì)算,并對(duì)候選答案進(jìn)行排序。在模型訓(xùn)練階段,設(shè)計(jì)了一種兩階段學(xué)習(xí)方法,采用聯(lián)合學(xué)習(xí)和對(duì)比學(xué)習(xí)來(lái)訓(xùn)練正向和反向推理。在模型預(yù)測(cè)階段,將正向和反向推理結(jié)合起來(lái),使用反向推理對(duì)正向推理的答案進(jìn)行反向檢驗(yàn),從而推斷出正確的答案。這種方法充分利用了知識(shí)圖譜中實(shí)體之間的正反向推理語(yǔ)義信息,不僅提高了問(wèn)答系統(tǒng)的性能和準(zhǔn)確性,同時(shí)答案也具備一定的可解釋性。
值得一提的是,當(dāng)前并沒(méi)有對(duì)應(yīng)的反向推理問(wèn)答數(shù)據(jù)集,同時(shí)推理路徑中往往缺少反向的邊,從而導(dǎo)致反向語(yǔ)義難以學(xué)習(xí)。為了克服這一困難,本文提出了一種新穎的反向語(yǔ)義推理評(píng)分函數(shù),它利用了復(fù)數(shù)向量?jī)?nèi)積運(yùn)算的對(duì)稱性,將反向計(jì)算轉(zhuǎn)換為正向計(jì)算。
![]()
其中,![]() 和
和![]() 分別代表答案實(shí)體和問(wèn)句實(shí)體的復(fù)數(shù)嵌入向量,而
分別代表答案實(shí)體和問(wèn)句實(shí)體的復(fù)數(shù)嵌入向量,而![]() 代表問(wèn)句的反向語(yǔ)義嵌入向量,
代表問(wèn)句的反向語(yǔ)義嵌入向量,![]() ,
,![]() 則表示共軛復(fù)數(shù)。
則表示共軛復(fù)數(shù)。
另外,在聯(lián)合學(xué)習(xí)中,本文采用一種新穎的較差者優(yōu)先評(píng)估策略來(lái)改進(jìn)雙向語(yǔ)義,其定義如下:
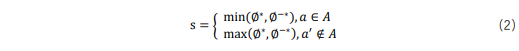
其中,![]() 為評(píng)估分?jǐn)?shù),指的是當(dāng)前候選節(jié)點(diǎn)作為正確答案的得分。具體而言,在訓(xùn)練過(guò)程中,當(dāng)
為評(píng)估分?jǐn)?shù),指的是當(dāng)前候選節(jié)點(diǎn)作為正確答案的得分。具體而言,在訓(xùn)練過(guò)程中,當(dāng)![]() 是正確答案時(shí),評(píng)估策略取
是正確答案時(shí),評(píng)估策略取![]() 和
和![]() 之間的較小值。相反,當(dāng)
之間的較小值。相反,當(dāng)![]() 不是正確答案時(shí),評(píng)估策略采用
不是正確答案時(shí),評(píng)估策略采用![]() 和
和![]() 之間的較大值。通過(guò)優(yōu)先優(yōu)化表現(xiàn)較差的方向,使得每次訓(xùn)練迭代都能夠獲得最大的收益。這樣的策略有助于模型更好地學(xué)習(xí)到正向和反向推理之間的關(guān)系,從而提高了模型在推理任務(wù)中的性能表現(xiàn)。
之間的較大值。通過(guò)優(yōu)先優(yōu)化表現(xiàn)較差的方向,使得每次訓(xùn)練迭代都能夠獲得最大的收益。這樣的策略有助于模型更好地學(xué)習(xí)到正向和反向推理之間的關(guān)系,從而提高了模型在推理任務(wù)中的性能表現(xiàn)。
同時(shí),在對(duì)比學(xué)習(xí)中,本文利用了一種新穎的對(duì)比損失函數(shù)。該對(duì)比損失函數(shù)為每個(gè)正樣本分配了加權(quán)分?jǐn)?shù),以反映其對(duì)反向語(yǔ)義推理![]() 的重要性。原因在于知識(shí)圖譜存在缺失信息的情況,同一個(gè)問(wèn)句對(duì)應(yīng)的不同正樣本與問(wèn)句的主實(shí)體之間的推理路徑可能不同,有的甚至缺失了重要的推理信息,導(dǎo)致整體推理的語(yǔ)義信息有強(qiáng)弱之分。該對(duì)比損失函數(shù)通過(guò)為每個(gè)正樣本分配了不同的加權(quán)分?jǐn)?shù),綜合了不同正樣本對(duì)損失函數(shù)的貢獻(xiàn),這里的加權(quán)分?jǐn)?shù)由正向語(yǔ)義推理獲得,代表了不同正樣本推理語(yǔ)義信息的強(qiáng)弱情況。
的重要性。原因在于知識(shí)圖譜存在缺失信息的情況,同一個(gè)問(wèn)句對(duì)應(yīng)的不同正樣本與問(wèn)句的主實(shí)體之間的推理路徑可能不同,有的甚至缺失了重要的推理信息,導(dǎo)致整體推理的語(yǔ)義信息有強(qiáng)弱之分。該對(duì)比損失函數(shù)通過(guò)為每個(gè)正樣本分配了不同的加權(quán)分?jǐn)?shù),綜合了不同正樣本對(duì)損失函數(shù)的貢獻(xiàn),這里的加權(quán)分?jǐn)?shù)由正向語(yǔ)義推理獲得,代表了不同正樣本推理語(yǔ)義信息的強(qiáng)弱情況。
該對(duì)比損失函數(shù)由以下方程定義:
![]()
其中,![]() 是訓(xùn)練數(shù)據(jù)集中的問(wèn)題數(shù)量,
是訓(xùn)練數(shù)據(jù)集中的問(wèn)題數(shù)量,![]() (
(![]() )是第
)是第![]() 個(gè)問(wèn)題的正(負(fù))樣本集。
個(gè)問(wèn)題的正(負(fù))樣本集。![]() 是
是![]() 中第i個(gè)實(shí)體的權(quán)重分?jǐn)?shù)。將從正向語(yǔ)義推理獲得的評(píng)估分?jǐn)?shù)通過(guò)softmax函數(shù)傳遞,得到
中第i個(gè)實(shí)體的權(quán)重分?jǐn)?shù)。將從正向語(yǔ)義推理獲得的評(píng)估分?jǐn)?shù)通過(guò)softmax函數(shù)傳遞,得到![]() 的權(quán)重分?jǐn)?shù)
的權(quán)重分?jǐn)?shù)![]() ,即:
,即:
![]()
實(shí)驗(yàn)結(jié)果及分析:
表1 MetaQA和WebQSP數(shù)據(jù)集的統(tǒng)計(jì)信息
表2 在MetaQA half-KG數(shù)據(jù)集上的結(jié)果
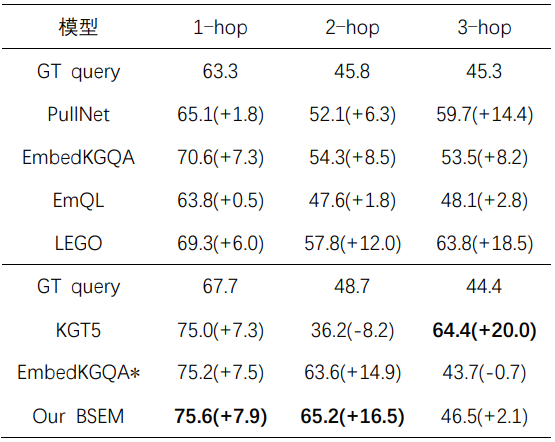
表3 在 WebQSP half-KG 數(shù)據(jù)集上的結(jié)果
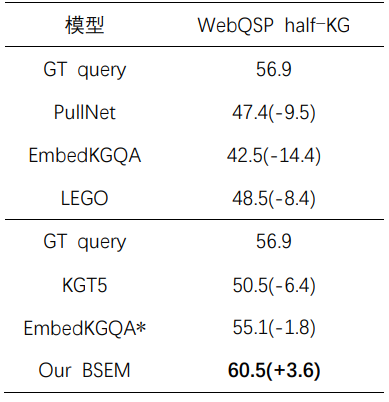
表4 在 WebQSP full-KG 數(shù)據(jù)集上的結(jié)果
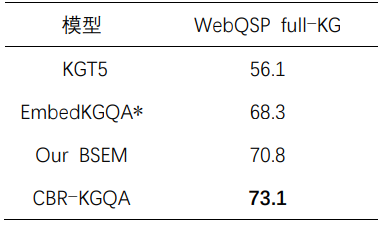
表5 消融實(shí)驗(yàn)
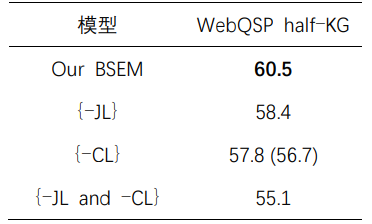
其中,“{-JL}”表示BSEM去除了聯(lián)合學(xué)習(xí);“{-CL}”表示去除了對(duì)比學(xué)習(xí);而“{-JL and -CL}”則刪除了聯(lián)合學(xué)習(xí)、對(duì)比學(xué)習(xí)和反向語(yǔ)義推理。因此,在“{-JL and -CL}”之后,BSEM退化為僅包含正向語(yǔ)義的EmbedKGQA。
表6 權(quán)重分?jǐn)?shù)的消融實(shí)驗(yàn)
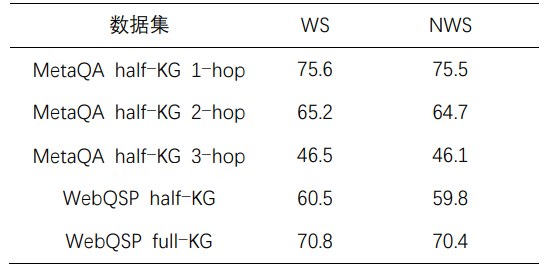
其中,“WS”代表本文方法,而“NWS”表示本文方法在對(duì)比學(xué)習(xí)中沒(méi)有使用加權(quán)分?jǐn)?shù)![]() 。
。
結(jié)論:
本章提出了基于雙向語(yǔ)義的知識(shí)圖譜問(wèn)答方法(BSEM),一種新穎的雙向語(yǔ)義嵌入和匹配方法,旨在緩解知識(shí)圖譜多跳問(wèn)答中正向語(yǔ)義漂移問(wèn)題,在提升答案準(zhǔn)確率的同時(shí)增強(qiáng)可解釋性。BSEM利用反向語(yǔ)義推理對(duì)正向語(yǔ)義推理的答案進(jìn)行反向檢驗(yàn),從而推斷出更準(zhǔn)確的答案。 在MetaQA和WebQSP兩個(gè)基準(zhǔn)測(cè)試上的實(shí)驗(yàn)表明,BSEM無(wú)論在half-KG還是full-KG中都能找到更準(zhǔn)確的答案,尤其是在稀疏的知識(shí)圖譜中,其性能提升顯著。而B(niǎo)SEM利用反向語(yǔ)義推理驗(yàn)證正向語(yǔ)義推理答案可信度的過(guò)程具備一定的可解釋性。
與PullNet、EMQL、LEGO、EmbedKGQA和KGT5等最先進(jìn)方法相比,BSEM在知識(shí)圖譜多跳問(wèn)答中具有最佳的整體性能。然而,BSEM只能緩解推理路徑中的語(yǔ)義漂移,而不能防止它。原因在于隨著推理路徑變得更長(zhǎng)或重要信息的缺失,正向和反向語(yǔ)義仍然會(huì)漂移。受KGT5模型啟發(fā),未來(lái)計(jì)劃探索基于雙向語(yǔ)義的編碼器-解碼器模型,通過(guò)語(yǔ)言模型引入更多的外部知識(shí),實(shí)現(xiàn)逐步推理校驗(yàn),以防止語(yǔ)義漂移。
通訊作者簡(jiǎn)介:
魯強(qiáng),副教授,博士生導(dǎo)師。目前主要從事演化計(jì)算和符號(hào)回歸、知識(shí)圖譜與智能問(wèn)答、以及軌跡分析與挖掘等方面的研究工作。聯(lián)系方式:luqiang@cup.edu.cn