
科研動(dòng)態(tài)
通過深度強(qiáng)化學(xué)習(xí)設(shè)計(jì)聯(lián)邦學(xué)習(xí)的安全服務(wù)契約激勵(lì)機(jī)制
中文題目:通過深度強(qiáng)化學(xué)習(xí)設(shè)計(jì)聯(lián)邦學(xué)習(xí)的安全服務(wù)契約激勵(lì)機(jī)制
論文題目:Secure Service-Oriented Contract Based Incentive Mechanism Design in Federated Learning via Deep Reinforcement Learning
錄用期刊/會(huì)議:IEEE 2024 International Conference on Web Services (ICWS) (CCF B)
錄用時(shí)間:2024年5月14日
作者列表:
1) 馬博聞 中國(guó)石油大學(xué)(北京) 信息科學(xué)與工程學(xué)院/人工智能學(xué)院 計(jì)算機(jī)科學(xué)與技術(shù)專業(yè) 碩21
2) 馮子涵 中國(guó)石油大學(xué)(北京) 信息科學(xué)與工程學(xué)院/人工智能學(xué)院 計(jì)算機(jī)科學(xué)與技術(shù)專業(yè) 碩22
3) 高煜洲 中國(guó)石油大學(xué)(北京) 信息科學(xué)與工程學(xué)院/人工智能學(xué)院 計(jì)算機(jī)科學(xué)與技術(shù)專業(yè) 本20
4) 陳 瑩 北京信息科技大學(xué) 計(jì)算機(jī)學(xué)院 教授
5) 黃霽崴 中國(guó)石油大學(xué)(北京) 信息科學(xué)與工程學(xué)院/人工智能學(xué)院 教授
摘要:
在聯(lián)邦學(xué)習(xí)中,確保本地模型所有者的積極參與,同時(shí)保護(hù)數(shù)據(jù)隱私和服務(wù)安全是一項(xiàng)艱巨的挑戰(zhàn)。我們的研究集中于兩種不同的信息場(chǎng)景:弱不完全信息場(chǎng)景和強(qiáng)不完全信息場(chǎng)景,它們對(duì)聯(lián)邦學(xué)習(xí)系統(tǒng)的完整性和效率提出了獨(dú)特的挑戰(zhàn)。在弱不完全信息場(chǎng)景中,我們需要解決本地模型所有者可能隱瞞其真實(shí)類型的問題。為此,我們使用契約理論及其自我揭示特性,確保本地模型所有者如實(shí)報(bào)告其類型。在強(qiáng)不完全信息場(chǎng)景中,我們認(rèn)識(shí)到本地模型所有者的動(dòng)態(tài)性質(zhì)及其隱私需求。我們提出了基于契約的深度強(qiáng)化學(xué)習(xí)(Contract-based Deep Reinforcement Learning, CDRL)算法,該算法結(jié)合了契約理論的戰(zhàn)略框架和深度強(qiáng)化學(xué)習(xí)的自適應(yīng)能力。CDRL算法旨在動(dòng)態(tài)環(huán)境中進(jìn)行實(shí)時(shí)契約設(shè)計(jì),使系統(tǒng)能夠有效應(yīng)對(duì)聯(lián)邦學(xué)習(xí)的參與,確保激勵(lì)措施與系統(tǒng)安全和學(xué)習(xí)目標(biāo)保持一致。通過在真實(shí)世界數(shù)據(jù)集上的廣泛實(shí)驗(yàn),我們提出的機(jī)制在激勵(lì)本地模型擁有者積極參與聯(lián)邦學(xué)習(xí)方面表現(xiàn)出色,從而顯著提高了系統(tǒng)性能。
背景與動(dòng)機(jī):
為了充分發(fā)揮聯(lián)邦學(xué)習(xí)模型的價(jià)值,我們需要建立合理的激勵(lì)機(jī)制,以確保系統(tǒng)參與者能夠自愿、無私地完成高質(zhì)量的數(shù)據(jù)計(jì)算工作。這一激勵(lì)機(jī)制應(yīng)能夠量化不同任務(wù)的工作量,并匹配相應(yīng)的獎(jiǎng)勵(lì),從而實(shí)現(xiàn)本地模型擁有者和任務(wù)發(fā)布者的利益最大化。由于本地模型擁有者通常不會(huì)向公眾披露其具體信息,因此實(shí)際應(yīng)用場(chǎng)景多為信息不對(duì)稱。然而,在現(xiàn)有研究中,激勵(lì)機(jī)制都是在本地模型擁有者分布已知、本地模型擁有者數(shù)量不變的假設(shè)下,利用凸優(yōu)化理論和契約理論進(jìn)行優(yōu)化設(shè)計(jì)的。此外,在本地模型擁有者分布未知且數(shù)量動(dòng)態(tài)變化的情況下,激勵(lì)機(jī)制的設(shè)計(jì)基本沒有研究。
主要內(nèi)容:
在這個(gè)框架中,我們有一個(gè)任務(wù)發(fā)布者,他將召集一些具有計(jì)算能力的本地模型擁有者來完成模型訓(xùn)練。具體來說,本地模型擁有者會(huì)根據(jù)其參與意愿,使其模型訓(xùn)練在數(shù)量和質(zhì)量上有所不同。因此,我們根據(jù)參與意愿的不同對(duì)所有本地模型擁有者進(jìn)行分類。在不失一般性的前提下,意愿越高,表明本地模型擁有者可以提供更高質(zhì)量或更多的數(shù)據(jù),為任務(wù)做出更大貢獻(xiàn),系統(tǒng)模型如如圖 1 所示。
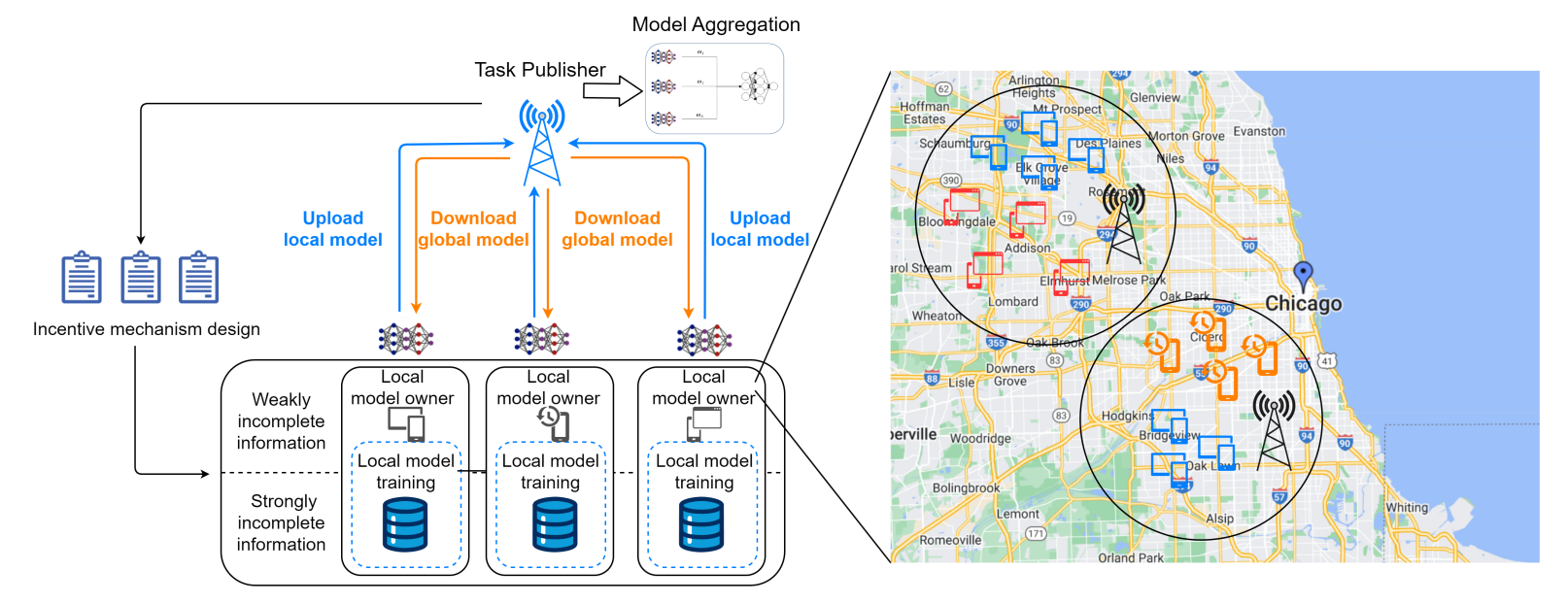
圖1 系統(tǒng)模型
為了激勵(lì)本地模型擁有者自愿無私地完成一定數(shù)量的任務(wù),任務(wù)發(fā)布者需要設(shè)計(jì)合理有效的激勵(lì)機(jī)制。本地模型擁有者有動(dòng)機(jī)隱藏自己的類型,假裝成其他類型的本地模型擁有者,以獲取更高的回報(bào)。此外,由于本地模型擁有者的意愿作為單個(gè)本地模型擁有者的私有數(shù)據(jù)沒有公開,因此任務(wù)發(fā)布者無法明確知道每個(gè)本地模型擁有者的具體類型。本地模型擁有者是自私而理性的,他們會(huì)在任務(wù)發(fā)布者提供的契約中選擇自身利益最大化的契約。任務(wù)發(fā)布者的效用由兩部分組成,即從模型訓(xùn)練中獲得的收益和支付給本地模型擁有者的成本;本模型擁有者的效用由兩部分組成,即從任務(wù)發(fā)布者的獎(jiǎng)勵(lì)和其模訓(xùn)練成本。定義為
![]()
![]()
在弱不完全信息情景中,本地模型擁有者的類型屬于私人信息,任務(wù)發(fā)布者不知道具體的本地模型擁有者的類型。為了防止本地模型擁有者為了獲得更高的效用而想隱瞞自己的類型,我們利用契約理論來解決這個(gè)激勵(lì)不對(duì)稱問題。通過契約理論,我們可以將原始優(yōu)化問題簡(jiǎn)化為以下形式:
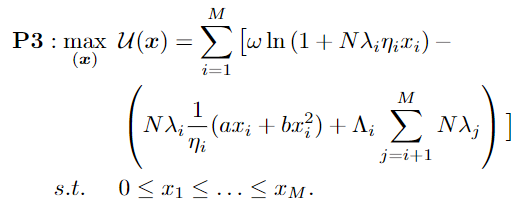
利用凸優(yōu)化工具,我們可以輕松得出最優(yōu)契約設(shè)計(jì)問題的最優(yōu)解,而無需考慮單調(diào)性條件的約束。當(dāng)本地模型擁有者的概率分布是均勻分布時(shí),解自然滿足單調(diào)性約束條件。否則,解有可能不滿足單調(diào)性約束。我們需要進(jìn)一步檢查解的單調(diào)性約束,使用“Bunching and Ironing”調(diào)整算法來解決不可行子序列問題。

然而,在現(xiàn)實(shí)中,本地模型擁有者的數(shù)量和分布可能是動(dòng)態(tài)的。本地模型擁有者的位置并不固定,可能會(huì)跨區(qū)域移動(dòng)。此外,本地模型擁有者也可能遇到不可預(yù)見的故障和其他不可預(yù)測(cè)的事件。鑒于本地模型擁有者的動(dòng)態(tài)性質(zhì)和隱私問題,我們建立了一個(gè)馬爾可夫決策過程(MDP)模型,并提出了一種深度強(qiáng)化學(xué)習(xí)算法CDRL,以應(yīng)對(duì)強(qiáng)不完全信息場(chǎng)景的挑戰(zhàn)。

實(shí)驗(yàn)結(jié)果及分析:
我們?cè)O(shè)計(jì)了大量模擬實(shí)驗(yàn),以評(píng)估弱不完全信息情景下契約設(shè)計(jì)的最優(yōu)性,以及強(qiáng)不完全信息情景下CDRL的性能。我們利用真實(shí)世界的數(shù)據(jù)Chicago Taxi Trips-2021進(jìn)行實(shí)驗(yàn)。通過使用K-means算法進(jìn)行區(qū)域劃分,劃分結(jié)果如圖2所示。
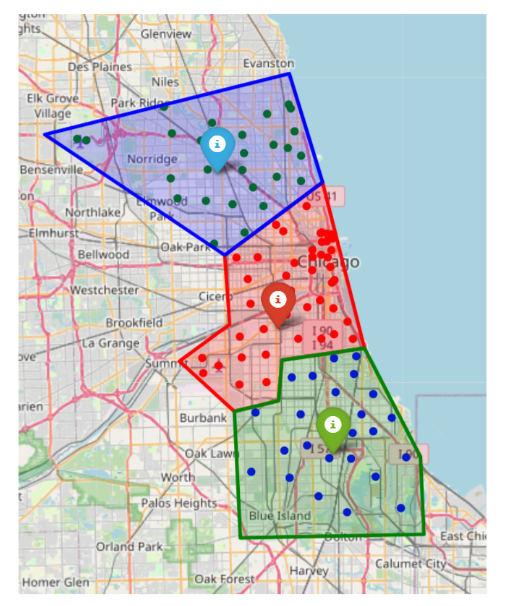
圖2 Chicago Taxi Trips – 2021
圖3顯示了本地模型擁有者在選擇任務(wù)發(fā)布者設(shè)計(jì)的不同契約條目時(shí)的效用。
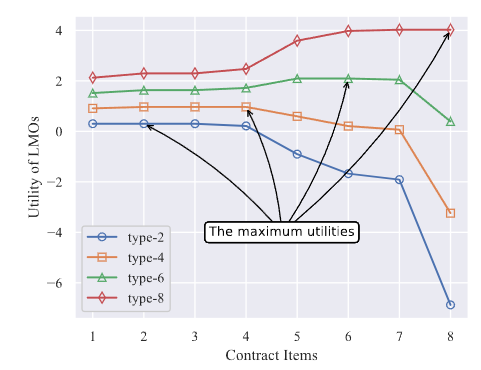
圖3 本地模型擁有者的效用
圖4展示了四種 DRL 算法的收斂性和性能。
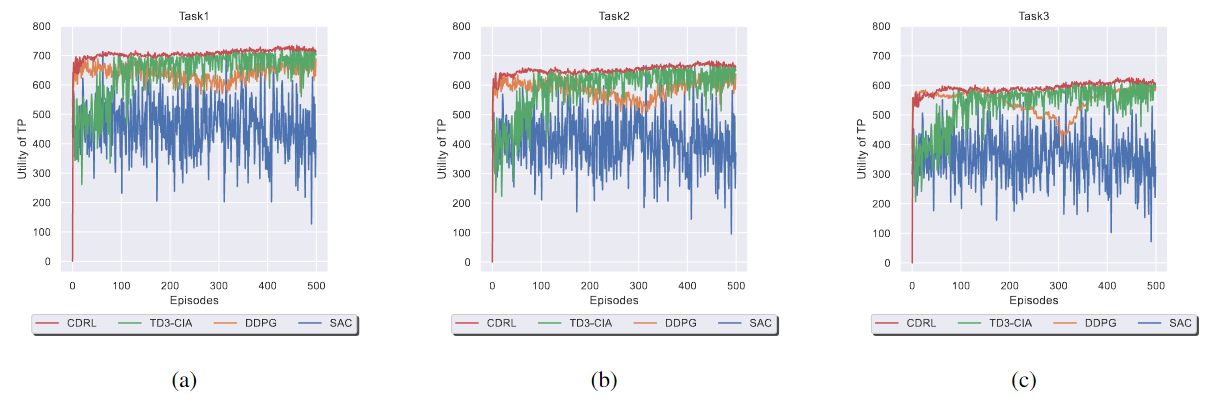
圖4 隨著訓(xùn)練回合數(shù)變化對(duì)性能的影響
(a) 任務(wù)1. (b) 任務(wù)2. (c) 任務(wù)3
結(jié)論:
在聯(lián)邦學(xué)習(xí)場(chǎng)景中,我們解決了如何在確保本地模型擁有者積極參與的同時(shí)維護(hù)隱私和安全的難題。我們探討了弱不完全信息和強(qiáng)不完全信息的場(chǎng)景,在前者中引入了契約理論等解決方案,在后者中引入了用于動(dòng)態(tài)自適應(yīng)的CDRL算法。我們的方法經(jīng)過真實(shí)世界數(shù)據(jù)的驗(yàn)證,顯著提高了本地模型擁有者的參與度和系統(tǒng)性能,展示了將博弈框架深度強(qiáng)化學(xué)習(xí)算法相結(jié)合以改進(jìn)聯(lián)邦學(xué)習(xí)系統(tǒng)的潛力。在今后的研究中,我們將改進(jìn)本地模型擁有者的分類,以詳細(xì)了解他們?cè)诼?lián)邦學(xué)習(xí)中的不同特點(diǎn)和作用。此外,我們還將探索使用包含離散和連續(xù)混合行動(dòng)空間的深度強(qiáng)化學(xué)習(xí)算法,以改進(jìn)激勵(lì)機(jī)制的設(shè)計(jì)和靈活性。
通訊作者簡(jiǎn)介:
黃霽崴,教授,博士生導(dǎo)師,中國(guó)石油大學(xué)(北京)信息科學(xué)與工程學(xué)院/人工智能學(xué)院副院長(zhǎng),石油數(shù)據(jù)挖掘北京市重點(diǎn)實(shí)驗(yàn)室主任。入選北京市優(yōu)秀人才、北京市科技新星、北京市國(guó)家治理青年人才、昌聚工程青年人才、中國(guó)石油大學(xué)(北京)優(yōu)秀青年學(xué)者。本科和博士畢業(yè)于清華大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)系,美國(guó)佐治亞理工學(xué)院聯(lián)合培養(yǎng)博士生。研究方向包括:物聯(lián)網(wǎng)、服務(wù)計(jì)算、邊緣智能等。已主持國(guó)家自然科學(xué)基金、國(guó)家重點(diǎn)研發(fā)計(jì)劃、北京市自然科學(xué)基金等科研項(xiàng)目18項(xiàng);以第一/通訊作者在國(guó)內(nèi)外著名期刊和會(huì)議發(fā)表學(xué)術(shù)論文60余篇,其中1篇獲得中國(guó)科協(xié)優(yōu)秀論文獎(jiǎng),2篇入選ESI熱點(diǎn)論文,4篇入選ESI高被引論文;出版學(xué)術(shù)專著1部;獲得國(guó)家發(fā)明專利6項(xiàng)、軟件著作權(quán)4項(xiàng);獲得中國(guó)通信學(xué)會(huì)科學(xué)技術(shù)一等獎(jiǎng)1項(xiàng)、中國(guó)產(chǎn)學(xué)研合作創(chuàng)新成果一等獎(jiǎng)1項(xiàng)、廣東省計(jì)算機(jī)學(xué)會(huì)科學(xué)技術(shù)二等獎(jiǎng)1項(xiàng)。擔(dān)任中國(guó)計(jì)算機(jī)學(xué)會(huì)(CCF)服務(wù)計(jì)算專委會(huì)委員,CCF和IEEE高級(jí)會(huì)員,電子學(xué)報(bào)、Chinese Journal of Electronics、Scientific Programming等期刊編委。
聯(lián)系方式:huangjw@cup.edu.cn