
動態(tài)學(xué)習環(huán)境中遷移專家場景的PlipPlop算法
中文題目:動態(tài)學(xué)習環(huán)境中遷移專家場景的PlipPlop算法
論文題目:The PlipPlop algorithm for migrating expert scenarios in dynamic learning environments
錄用期刊/會議:CCC2025 (CAA A類會議)
錄用時間:2025.1.2
作者列表:
1)宋宇 中國石油大學(xué)(北京)人工智能學(xué)院 自動化系 教師
2)周佳佳 中國石油大學(xué)(北京)人工智能學(xué)院 控制科學(xué)與工程 研18級
3)代思怡 中國石油大學(xué)(北京)人工智能學(xué)院 控制科學(xué)與工程 研23級
4)劉建偉 中國石油大學(xué)(北京)人工智能學(xué)院 自動化系 教師
摘要:
首先,我們選擇相對熵損失函數(shù)作為自適應(yīng)權(quán)值動態(tài)更新工具,用于獲取遷移專家學(xué)習場景的后悔上界。 其次,參考在線觸發(fā)器算法的討論,推導(dǎo)了如何自適應(yīng)地動態(tài)調(diào)整學(xué)習速率。我們也得到了學(xué)習率的上界。 最后將學(xué)習率的上界轉(zhuǎn)化為后悔函數(shù)的上界,討論了如何在后悔函數(shù)上得到一個更小的上界,實現(xiàn)超參數(shù)的自適應(yīng)調(diào)整。
主要內(nèi)容:
定理:假定,
,
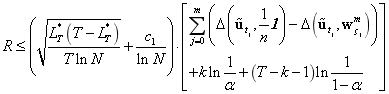
這里,
Theorem 10: 假定, 權(quán)重
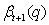 服從:
服從:
這里
比較序列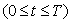 具有k次遷移:
具有k次遷移:
權(quán)值更新算法
具有下列后悔上界:
這里,
結(jié)論:
本文將2014年De Rooij等人提出的在線觸發(fā)器算法應(yīng)用于遷移專家,討論了學(xué)習率的優(yōu)化和調(diào)整對學(xué)習效果的影響。遷移專家場景在不同的區(qū)域有不同的模型,所以我們首先使用混合權(quán)重更新公式來討論在線學(xué)習中的遷移場景,通過混合前一刻的權(quán)重,很大程度上可以減少遷移帶來的損失,從而得到一個新的誤差上界。混合權(quán)重更新公式可以解決稀疏復(fù)雜模型的問題,該方法對許多真實數(shù)據(jù)集非常有效。同時,考慮到在遷移場景中,很難在不同的學(xué)習階段給出一個最優(yōu)的學(xué)習速率,在線觸發(fā)器算法可以通過調(diào)整相同概率分布產(chǎn)生的數(shù)據(jù)或不同概率分布產(chǎn)生的數(shù)據(jù)的學(xué)習率來獲得更好的學(xué)習效果,因此,觸發(fā)器算法為本文的討論提供了完整的理論基礎(chǔ)。我們討論了損失函數(shù)和近似損失函數(shù)之間的差來設(shè)置學(xué)習率的切換條件,學(xué)習率可以實時地選擇和切換,以實現(xiàn)遷移專家場景中學(xué)習率的調(diào)整。實驗結(jié)果進一步驗證了將觸發(fā)器算法應(yīng)用于遷移專家在線學(xué)習,可以獲得更小的后悔上界。
作者簡介:
劉建偉,教師。